Python爬虫支持的网页解析技术有几种?这几种技术有什么特点?
时间:2021-06-13 14:50:14浏览:4377
Python支持一些解析网页的技术,分别为正则表达式、XPath、Beautiful Soup和JSONPath,其中:
针对文本的解析,有正则表达式;
针对HTML/XML的解析,有XPath、Beautiful Soup、正则表达式;
针对JSON的解析,有JSONPath。
那么,这几种技术有什么区别呢?
正则表达式基于文本的特征来匹配或查找指定的数据,它可以处理任何格式的字符串文档,类似于模糊匹配的效果。
XPath和Beautiful Soup基于HTML/XML文档的层次结构来确定到达指定节点的路径,所以它们更适合处理层级比较明显的数据。
JSONPath专门用于JSON文档的数据解析。
针对不同的网页解析技术,Python分别提供了不同的模块或者库来支持。其中,re模块支持正则表达式语法的使用,lxml库支持XPath语法的使用,json模块支持JSONPath语法的使用。此外,Beautiful Soup本身就是一个Python库,官方推荐使用beautifulsoup4进行开发。
正则表达式、XPath和Beautiful Soup都能实现网页的解析,那么实际开发中应该如何选择呢?接下来,通过一张表来比较一下re、lxml和beautifulsoup4的性能,如表1所示。
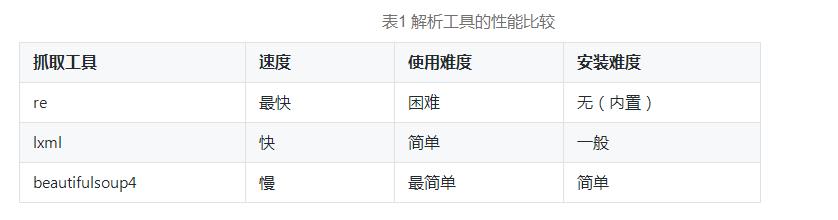
lxml库是用C语言编写的,beautifulsoup4库是用Python编写的,所以性能会差一些。但是,beautifulsoup4的API非常人性化,用起来比较简单,而lxml使用的XPath语法写起来比较麻烦,所以开发效率不如beautifulsoup4。
此外,lxml只能局部遍历树结构,而beautifulsoup4是载入整个文档,并转换成整个树结构。因此,beautifulsoup4需要花费更多的时间和内存,性能会稍低于lxml。
通过表1中对三种技术的比较,大家在实际开发中可根据具体情况选择适合自己的技术。
上一篇:jpg怎样转换成pdf
下一篇:file_get_contents(): SSL operation failed with code 1

- Linux文章
- PHP文章
- 随机文章
- 让nginx支持ssi
- Linux中的find(-atime...
- mysql的expire_logs_...
- PHP 扩展 libsodium s...
- Linux下利用find和cp实现筛...
- 使用mysqldump命令导出备份m...
- Linux系统如何设置开机自动运行脚...
- Linux上实现秒级执行的定时任务
- shell echo -e 颜色输出
- Linux下通过grep查找指定的进...
发表评论
昵称: 验证码: